PixelRNN
by Huigyu Yang, Ju Hun Lee
Pixel Recurrent Neural Networks
- van den Oord, A., Kalchbrenner, N. & Kavukcuoglu, K., “Pixel Recurrent Neural Networks.” Proceedings of The 33rd International Conference on Machine Learning, in Proceedings of Machine Learning Research, 2016.
Summary
- 이미지의 픽셀 생성시 Recurrent Neural Network(RNN)를 사용하며 다음 세 가지 Row LSTM, Diagonal Bi-LSTM, PixelCNN 모델을 제안한다.
- $i$ 번째 픽셀을 (1 ~ $i-1$ )번째 픽셀을 이용하여 추론하는 Auto regressive propety를 갖고 tractable하다. 또한 log-liklihood측면에서 가장 우수한 성능을 보인다.
- RNN의 특성으로 모든 이전 픽셀을 전부 사용할 경우 속도에 한계가 있어 receptive field를 삼각형으로 구성한다.
- Diagonal Bi-LSTM은 $i-1$번째까지의 모든 픽셀을 사용하도록 구현되어 느리지만 성능이 우수하다.
Preliminaries
Autoregressive를 갖는 PixelRNN은 이미지 생성시 $i$번째에 있는 픽셀 $x_i$의 확률 $p(x_i)$를 $i$보다 이전에 있는 픽셀을 이용해 구한다.
If the image $x$ is given as a one-dimensional sequence $𝑥_1,𝑥_2,…, x_{n^2}$, the joint distribution $𝑝(x)$ is written as:
\[\begin{align} p(x) = \Pi^{n^2}_{i=1}p(x_i|x_1, ..., x_{i-1}) \end{align}\]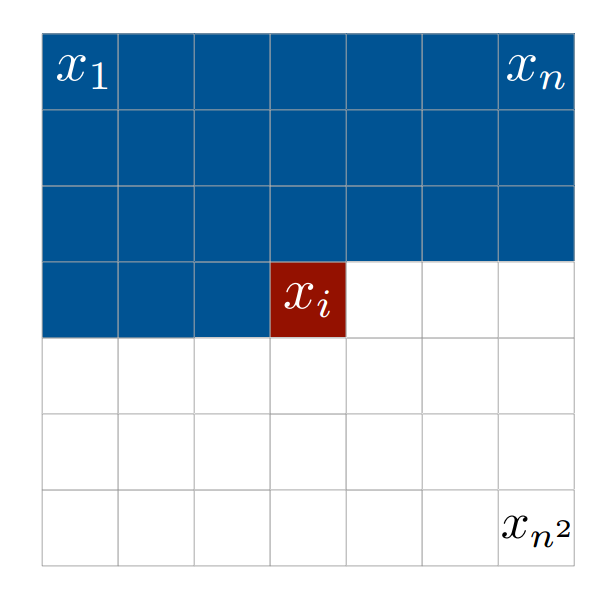
즉, Autoregressive를 따르는 모델은 새로운 픽셀의 확률분포를 주어진 다른(이전) 픽셀들의 확률분포로 구한다.
Models
이 섹션에서는 앞서 언급한 세개의 모델중 RNN을 활용하는 RowLSTM과 Diagonal Bi-LSTM을 활용한 모델을 설명한다. 이 섹션의 핵심은 autoregressive property를 지키면서 최대한 넓은 receptive field를 갖도록 각 RNN모델들의 적용방식이다.
Row LSTM
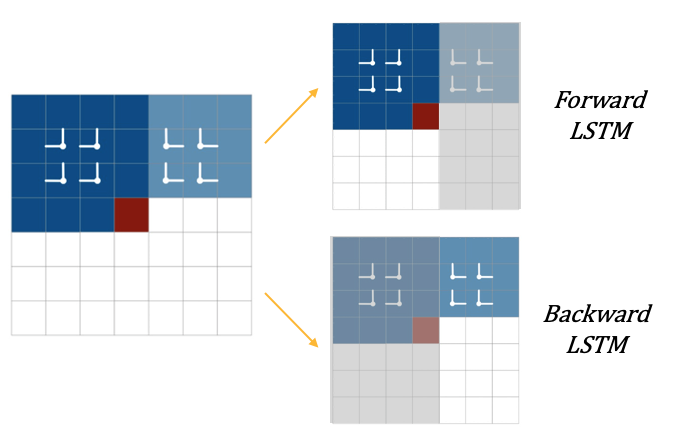
Row LSTM은 1D 컨볼루션으로 이미지를 행별로 처리하면서 receptive field는 아래 그림과 같이 삼각형 형태를 취한다.
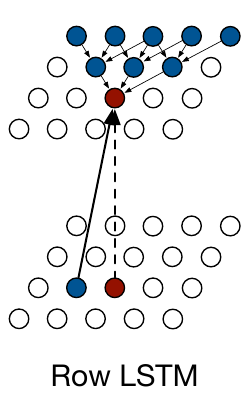
일반적으로 삼각형 형태로 인해 모든 이전 픽셀을 활용하지 못한다고 생각할 수 있으나 이전 셀의 값을 입력으로 받아 연산하는 LSTM의 특성으로 이를 극복한다.
- Long Short Term Memory (LSTM)
- LSTM은 다음 input to state와 state to state을 계산한다. 각 셀 내에서 네트워크는 4개의 게이트를 통해 PixelRNN에서 입력-상태 구성요소는 먼저 행별로 이동하는 $k x 1$ 크기의 컨볼루션으로 전체 입력 맵에 대해 계산된다. 컨볼루션에서는 이전 픽셀만 포함하도록 마스킹되고(Masking 섹션에서 다룰예정) $4h, n, n$ 크기의 텐서를 생성합니다. 여기서 $h$는 출력 피쳐 맵의 크기이고 $n$은 이미지 치수이며 4는 LSTM 셀의 게이트 벡터 수입니다. 그런 다음 이전 상태에 컨볼루션을 적용하여 상태 대 상태 성분을 계산한다.
- 수식은 아래와 같다:
Note: $\times$ refers a convolution and $\cdot$ refers a dot production.
위와 같이 LSTM을 활용함에도 불구하고 아래 그림과 같이 어떤 셀 $x_i$ 와 같은 행에 있는 픽셀의 값을 참조하지 못하는 문제가 발생한다. 논문에서는 이를 위해 입력의 바로 왼쪽에 있는 셀(e.g., 초록색 셀)을 입력으로 제공한다.
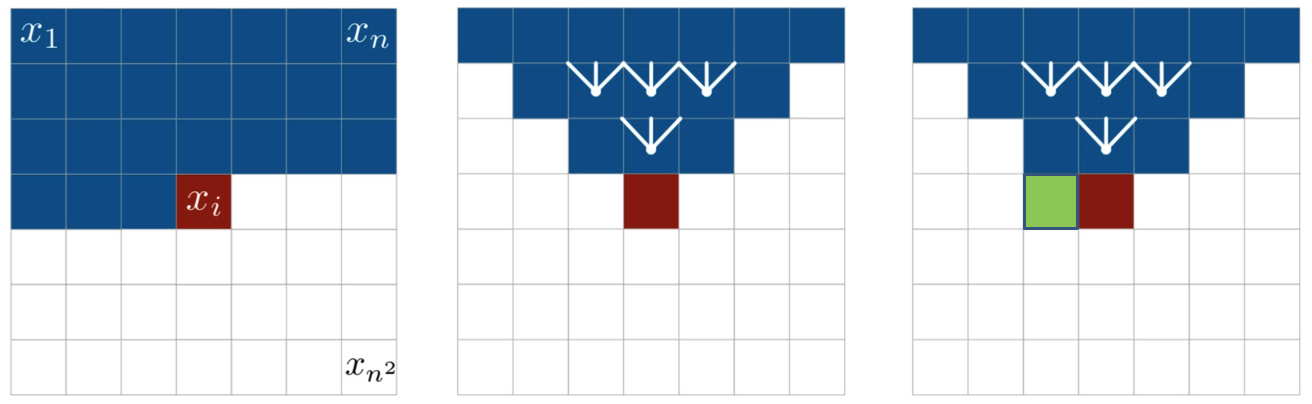
Diagonal LSTM
Diagonal LSTM은 삼각형태를 갖는 receptive field를 이상적인 형태 (i.e., 이전 모든 셀을 포함하는)로 만들기 위해 양방향 연산을 활용하는 Bidirectional LSTM을 사용한다.
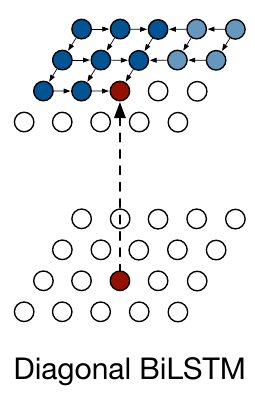
- 레이어의 두 방향 각각은 상단의 코너에서 시작하여 하단의 반대쪽 코너에 도달하는 대각선 방식으로 이미지를 사용한다.
- 이로 인해 가장 넓은 receptive field를 갖게 되지만 두번의 연산과정으로 인해 제일 긴 계산시간을 갖는다.
- 구현방식에 있어서 Scewed Convolution을 제안한다.
- 이로인해 LSTM의 특성을 이용하면서도 효율적인 병렬 연산이 가능하다. 이해를 돕기 위한 그림은 아래와 같다.
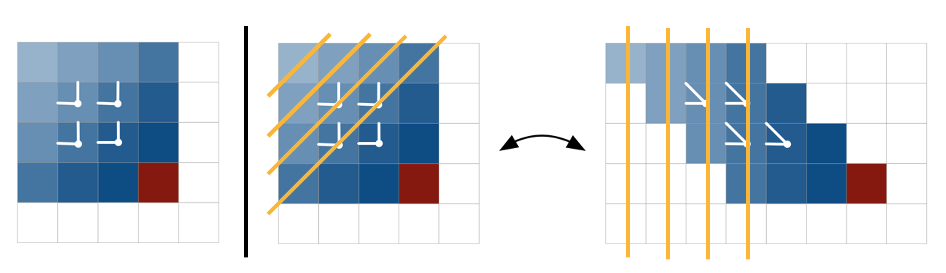
전체 연산 흐름은 다음과 같다. 먼저 input 맵을 이전 맵에 대해 각 행 $offset$이 1픽셀씩 있는 새 맵으로 왜곡하여 계산한다(scewed computation). 새 입력 맵의 최종 크기는 $n x *(2n-1)$ 이다. 두 방향 각각에 대해 input-state 구성요소( $1\times 1$ 컨볼루션)가 계산된다. state-state 구성 요소는 커널 크기( $2\times1$ )를 가진 열별 컨볼루션으로 계산된다. 출력 피쳐 맵은 $n \times n$ 차원으로 다시 압축된다.
정리하자면 diagnoal LSTM은 완전한 의존성 필드를 가지고 있다는 것이다. 또한 많은 수의 작은 계산( $2 \times 1$ 커널)을 사용함으로써 비선형적인 계산을 산출해 표현력이 향상된다고 생각한다.
Maskings and Residuals
Maskings
Autoregressive 모델을 구성하기 위해서는 데이터간 dependency 순서를 정해주는 것이 핵심적인데 이미지 픽셀의 dependency는 왼쪽위에서 오른쪽 아래 방향(본 포스팅의 첫 figure를 참조)으로 정의하고 색깔은 RGB 채널순서대로 종속성을 정의한다.
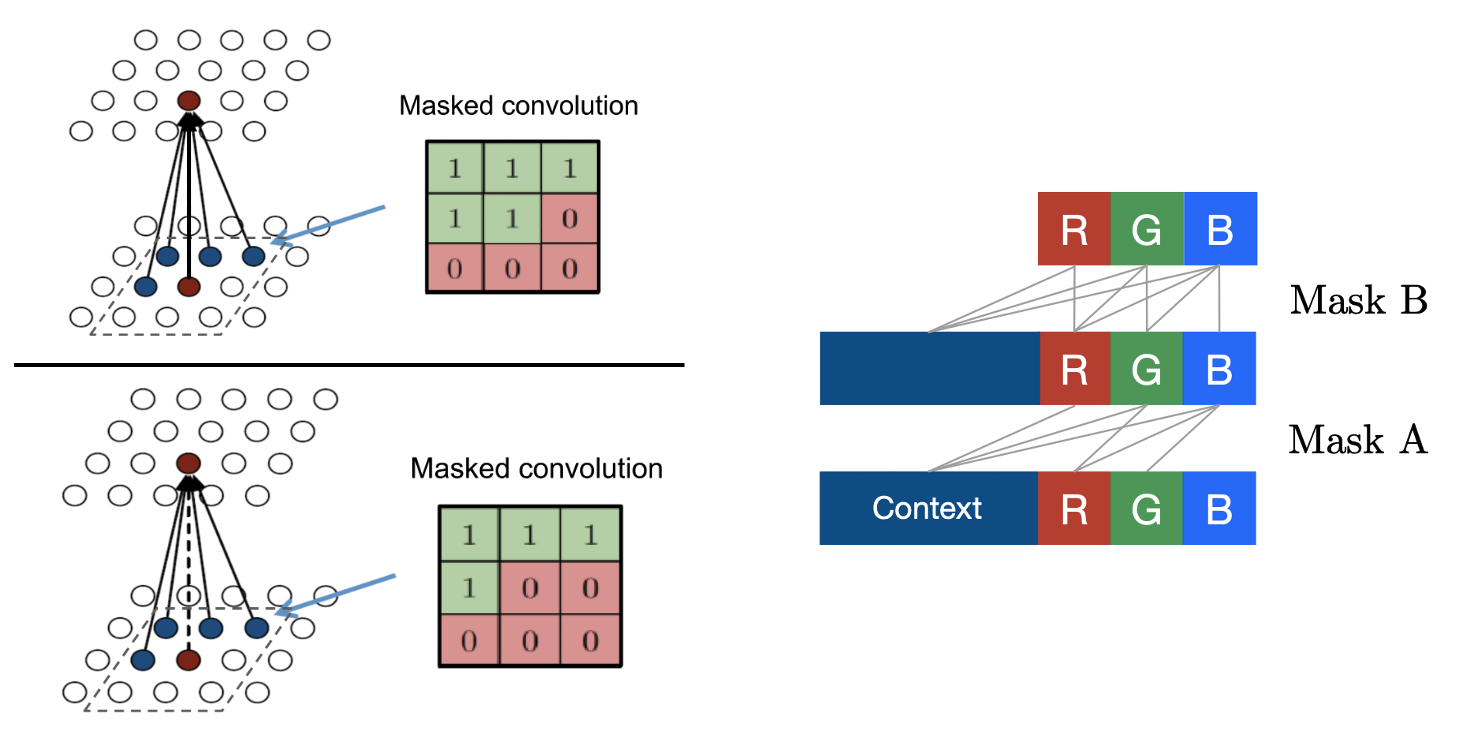 위의 그림은 이전 셀만을 사용하도록 마스킹하는 것과 채널순서에 따라 마스킹하는 것을 함께 나타낸 그림이다. 위 그림에서 먼저 아래쪽그림들은 Mask A로 논문에선 기술되며 autoregressive property를 위해 셀 자신 이전의 셀만 입력되도록 마스킹 하는 것을 알 수 있다. 아래쪽에서 우측의 RGB채널들간 마스킹 역시 R채널은 이전 셀까지의 모든 정보를, G채널은 이전 셀 + R채널까지, B채널은 G채널까지 활용하도록 마스킹을 사용한다. 위 그림에 위쪽에 나타낸 그림들은 Mask B로 논문에서 기술하고 있으며 자기 셀 자신, 채널에선 동채널까지 입력으로 사용하고 있다.
위의 그림은 이전 셀만을 사용하도록 마스킹하는 것과 채널순서에 따라 마스킹하는 것을 함께 나타낸 그림이다. 위 그림에서 먼저 아래쪽그림들은 Mask A로 논문에선 기술되며 autoregressive property를 위해 셀 자신 이전의 셀만 입력되도록 마스킹 하는 것을 알 수 있다. 아래쪽에서 우측의 RGB채널들간 마스킹 역시 R채널은 이전 셀까지의 모든 정보를, G채널은 이전 셀 + R채널까지, B채널은 G채널까지 활용하도록 마스킹을 사용한다. 위 그림에 위쪽에 나타낸 그림들은 Mask B로 논문에서 기술하고 있으며 자기 셀 자신, 채널에선 동채널까지 입력으로 사용하고 있다.
정리하자면, Mask A로 어떤 셀 $x_i$ 이전까지의 셀로 한번 계산을 한 결과이기 때문에 Mask B계산에서 $x_i$의 위치를 포함시켜도 autoregressive property가 유지된다.
Residuals
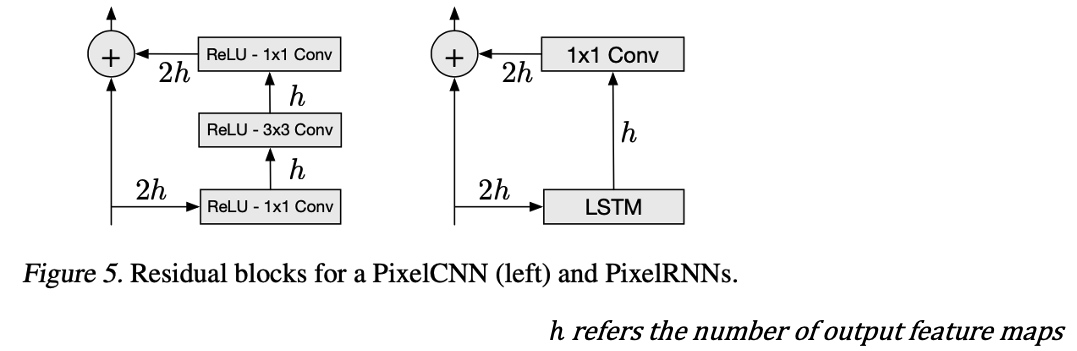
Pixel RNN은 최대 12단 LSTM을 사용하는데 이때의 그라데이션 소실 또는 폭발 문제를 방지하기 위해 residual connection을 활용한다.
- input-state 연산에서 게이트당 $h$ 크기의 피쳐를 생성함으로써 피쳐의 수를 줄이며, 이는 $1\times1$ Conv를 통해 업샘플링된다.
- Skip connection 또한 residual connections의 일부로도 활용되며 각 계층에서 skip connection을 사용하여 결과를 출력한다.
- Pixel CNN과 RNN간 다른 형태의 residual connection이 사용되면 그림은 아래와 같다.
Performance
모델 측면에서의 비교
먼저 논문에 소개된 모델들을 비교하자면 다음과 같다. |Models|Receptive Field|Computation Time|likelihood| |:—:|:—:|:—:|:—:| |Pixel CNN|Relatively larger blind spot|Faster (or Fastest)|Worst| |Pixel RNN(Row LSTM)|Triangularly covered receptive field|-|-| |Pixel RNN(Diagonal LSTM)|Fully covered receptive field|Slowest|Best|
또한 앞서 설명한 residual connection 및 layer의 수에 따른 결과 비교는 다음과 같다.


보인바와 같이 residual과 skip connection을 활용해 깊은 신경망을 쌓았을때 NLL결과가 가장 낮은 것을 확인할 수 있다.
실험 결과에 따른 이미지 비교
CIFAR-10과 ImageNet 데이터셋을 통해 보인 정성적 결과들은 다음과 같다.
 아래 결과는 이미지 생성 테스트를 한 결과이며 가장 우측에 있는 그림이 원본이다. 중간에 있는 그림들이 모델이 출력한 결과이다.
아래 결과는 이미지 생성 테스트를 한 결과이며 가장 우측에 있는 그림이 원본이다. 중간에 있는 그림들이 모델이 출력한 결과이다.

Conclusion
이 포스팅을 통해 PixelRNN에 대한 이해도가 높아졌길 바라며 정리한 이 논문의 핵심은 다음과 같다. pixelrnn은 새로운 픽셀의 확률 분포를 주어진 다른 픽셀들의 확률 분포로 가정한다. 그리고 각 픽셀의 색(RGB)의 값들도 순서대로 conditional하게 주어진다고 가정한다. 그리고 각 픽셀의 값의 분포를 continuous가 아닌 discrete로 가정하고 softmax를 통하여 추정하였다. 이렇게 다른 픽셀들로 부터 sequential하게 정보를 받는 방법으로 세가지 모델을 제안하였다. Pixel Recurrent Neural Networks라는 논문에서 PixelRNN, PixelCNN이 갖고 있는 구조가 모두 소개된다.
- NLL을 기준으로 하였을때 기존보다 나은 image generation이 이루어졌다. PixelRNN은 이산 분포를 사용하여 이미지를 모델링하며, 이를 통해 모델이 더 나은 NLL 결과를 갖도록 이끈다.
- 모델에서 LSTM을 사용해 autoregressive모델을 구현하는 두 가지 다른 방법이 제안되며, 이는 주어진 task의 조건(성능 및 시간)에 따라 선택을 가능하게 한다.
Subscribe via RSS