Neural Autoregressive Distribution Estimator (NADE)
by Janghun Kim, Hyogeun Byun
Larochelle, Hugo, and Iain Murray. “The neural autoregressive distribution estimator.” Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011.
1. Abstract and Motivation
Abstract
본 논문은 이산 변수의 high-dimensional vector distribution을 modeling하는 새로운 접근 방식을 제시하고 있습니다.
본 논문에서 제시되는 모델은 Restricted Boltzmann Machines (RBM)에서 영감을 얻었으며, 이는 그러한 분포의 강력한 model로 나타났습니다.
그러나, RBM은 일반적으로 다루기 쉬운 Density Estimator를 제공하지 않습니다. 왜냐하면 RBM이 주어진 관측에 할당하는 확률을 평가하려면 소위 partition function의 계산이 필요하기 때문입니다. 이 partition function 자체는 중간 크기의 RBM에도 다루기 어렵습니다.
본 논문의 model은 관측치의 joint distribution를 다루기 쉬운 conditional distribution으로 분해하고 유사한 비선형 함수를 사용하여 각 조건을 모델링합니다.
또한 출력이 관측치에 유효한 확률을 할당하는 데 사용될 수 있도록 연결된 Auto-Encoder로 해석될 수 있습니다.
이러한 새로운 model이 여러 data set에서 다른 다변량 이진 분포 추정기를 능가하고 대형 RBM과 유사하게 수행된다는 것을 보여줍니다.
What the paper wishes to achieve?
본 논문이 이루고자 하는 것부터 먼저 설명해보면, high dimensional 한 discrete/binary vector들의 Distribution Estimation 이다.
Why is this problem Important?
이러한 문제들이 중요한 이유는 object들의 joint distribution을 알고있다면, 모든 supervised learning을 포함하여 object 간의 dependency에 대한 모든 질문에 답하기 시작할 수 있기 때문이다.
2. Previous Approaches
Restricted Boltzmann Machines (RBMs)
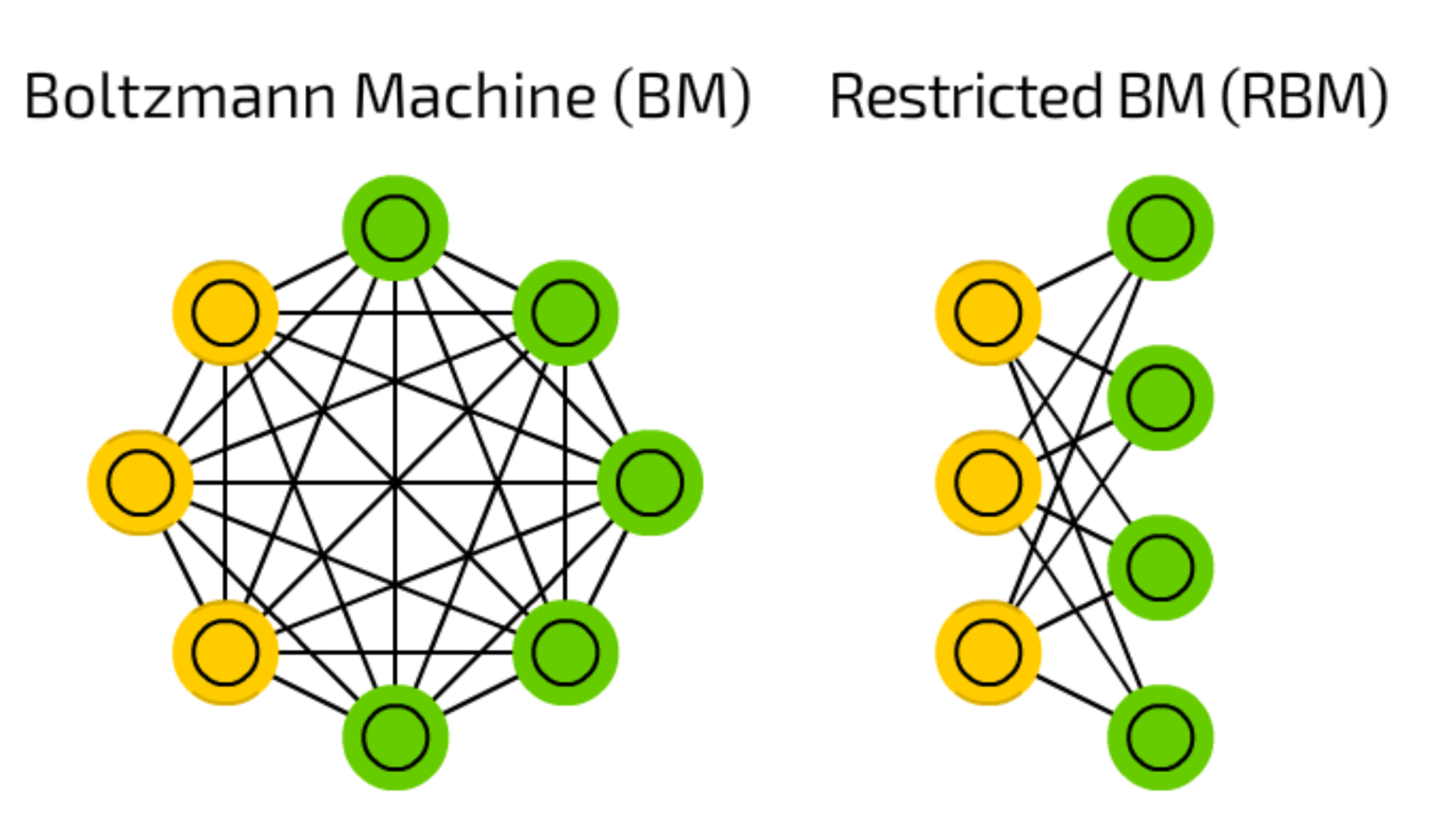
Energy function을 이용하여 Probability를 구하지만, 다양한 문제가 존재한다.

- Computing partition function $Z$는 소규모 network를 제외한 모든 network에서 intractable 하며 근사가 필요로 합니다.
- RMM은 probabilistic system의 일부를 modeling 하는 데 사용할 수 없습니다.
- 학습된 distribution을 평가하는데 어려움이 있습니다.
Bayesian Networks

다들 아시는 내용이지만, Bayesian Networks의 주요 strategy는 conditionals를 사용하여 distribution을 decomposing하는 것 입니다. 예를 들어, Fully Visible Sigmoid Belief Networks는 위와 같습니다.
이외에도 Markov Assumption과 같이 파라미터의 개수를 지수차원에서 끌어내릴 수 있는 등의 기법을 사용하여 본 NADE의 연구가 진행되었습니다.
3. Neural Autoregressive Distribution Estimator (NADE)
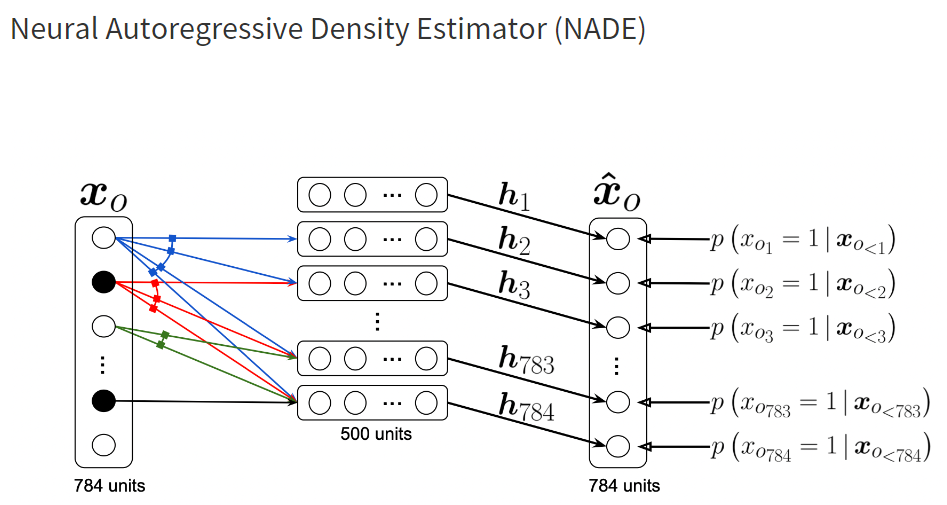
NADE의 Architecture는 위와 같으며, 가중치 matrix $W$를 공유하는 것을 확인할 수 있습니다. 이처럼 weight의 길이가 가변적인게 중요 특징입니다. 그리고 next input에 대해서도 이전 Weight를 재활용하는 식의 strategy를 사용하여 computational cost가 절감되며, 빠르게 진행될 수 있다는 것을 알 수 있습니다.
NADE는 이 확률을 토대로 해당 이미지를 판별하는 discriminator 역할을 수행하며 그래서 논문 제목이 Density Estimator라고 단어가 붙여졌습니다.
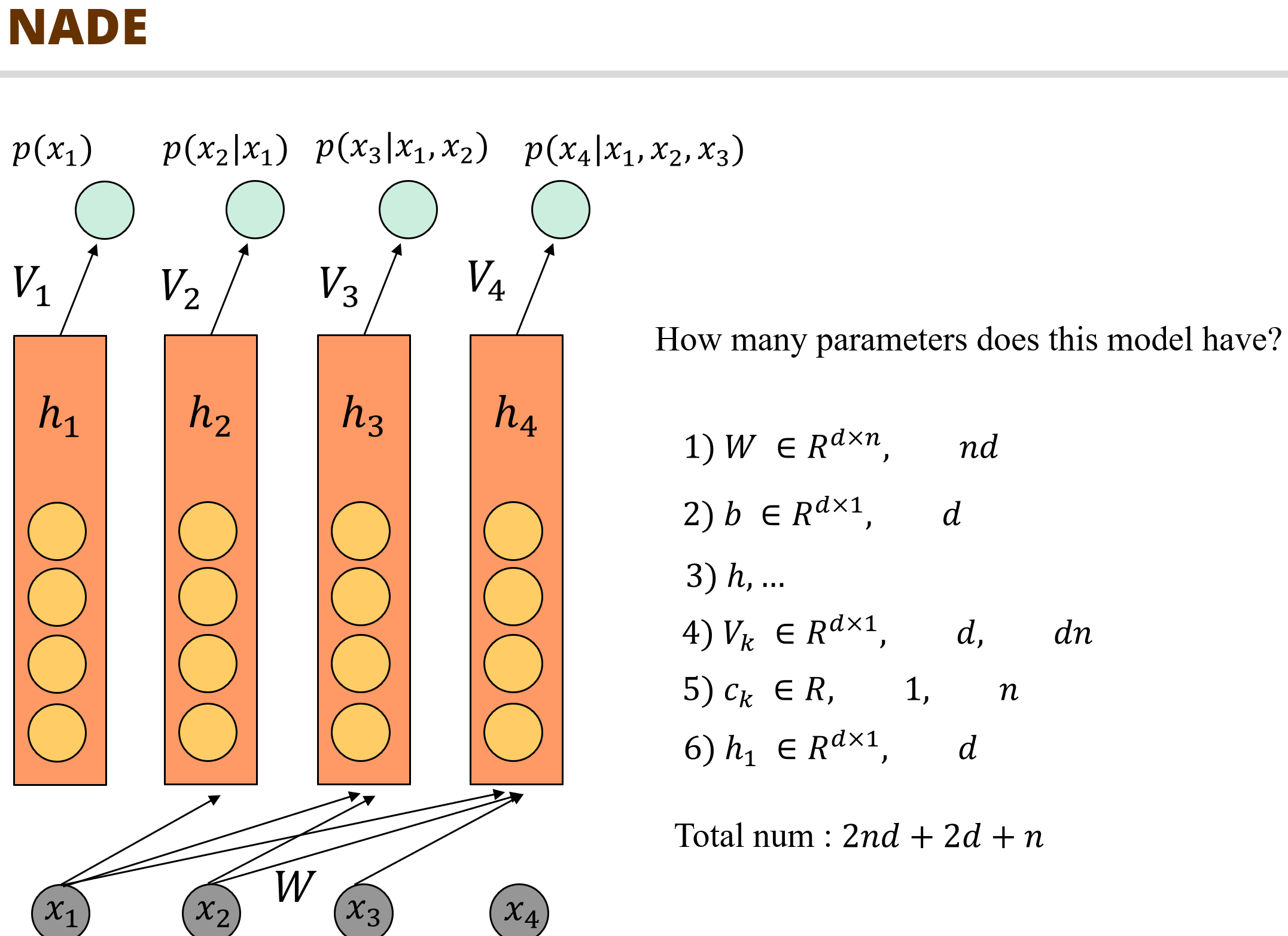
NADE 네트워크에서 사용되는 파라미터를 계산한 결과인데 이는 weight matrix를 공유함으로써 파라미터 수가 상당히 적은 것을 확인할 수 있습니다.
NADE의 작동 방식은 다음과 같습니다.
- i 번째 픽셀을 1 ~ i-1 번째 픽셀에 의존하도록 conditionals를 사용합니다.
- 즉, 첫 번째 픽셀의 확률분포는 독립적으로 만들고, 두 번째 픽셀의 확률은 첫 번째 픽셀에 의존하도록 구성
- NADE는 explicit model (생성 + 확률 계산) -> 주어진 입력에 대해 density 계산 가능
- 연속 확률 변수일 때는 마지막 모델에 가우시안 믹스쳐 모델을 사용

위는 실제 NADE의 구현이며 참고해보시면 좋을 것 같습니다.
4. Summary
- Uses the explicit representation of the joint distribution
NADE는 explicit model이어서 단순 generation 뿐만이 아니라 임의의 input에 관해서도 확률을 계산할 수 있다.즉, 임의의 input에 관해 독립적으로 확률을 explicit하게 계산할 수 있다. Continuous한 random variable을 modeling 할 경우 Gaussian distribution을 사용한다.
- Reduces the number of parameters by sharing weights in the neural network
계속 언급했듯이 weight가 가변적이라 파라미터를 공유하고 이로 인해 computational cost와 memory cost가 절감되는 것을 알 수 있다.
- Generation is slow because the model generates one pixel at a time
Generation은 순차적으로 진행되어 느리지만, 그 안에서도 cost를 줄이기 위한 노력을 하는 것을 볼 수 있다. 이후의 생성 모델들은 이러한 점을 보완하여 한번에 생성되는 모델들이 제시된다.
- Possible to speed up the computation by reusing some previous computations
weight가 사전에 사이즈가 할당되어있고, step이 진행될 수록 이전 weight를 포함하고 한 column이 더 들어와 reusing 하는 형식인 것을 알 수 있으며 이로 인한 computational cost가 절감된다.
Subscribe via RSS