Generating Diverse High-Fidelity Images
by Seunghoon Lee
Generating Diverse High-Fidelity Images With VQ-VAE-2
Ali Razavi, Aaron van den Oord, Oriol Vinyals [NeurIPS 2019]
1. Introduction
Deep Generative model은 최근 크게 발전하여 다양한 분야에서 현실의 데이터와 구분이 불가능 한 정도가 되었다. 본 논문에서는 생성 모델을 VAE, flow based, autoregressive model 들이 포함된 likelihood based model과 GAN과 같은 implict generative model로 나눈다.
해당 논문이 발표 된 2019년도에는 생성모델 중 가장 각광 받는 모델 중 하나로 GAN을 꼽았을 것이다. GAN과 같은 adversarial 모델은 빠르게 발전하여, 높은 퀄리티와 해상도를 갖는 데이터를 생성할 수 있는 Larger scale GAN 모델이 다수 공개 되며 타 모델들과도 비견되는 state-of-the-art 성능을 보였다. 하지만, 본 논문의 저자들은 GAN의 단점들을 조명하며 이에 반해 negative log-likelihood(NLL) 기반으로 작동하는 likelihood based model의 장점을 강조한다.
GAN 단점
- 한 레이블에 대한 다수의 이미지가 갖고 있는 실제 분포를 담지 못한다.
- 성능에 대한 평가가 어렵고 실존하지 않는다.
- Overfitting을 평가하기 위한 test set에 대한 일반화가 존재하지 않는다.
2. Background
VQ-VAE2에 대해 설명하기 전, 몇 가지를 사전에 알아두고 가야 이해가 용이하다. VQ-VAE2는 VQ-VAE를 개량시켜 성능을 향상시킨 논문으로써 prior는 PixelSnail논문에서의 아이디어를 사용하여 모델링 했다. 해당 장에서는 VQ-VAE와 PixelSnail에 대해 간단하게 설명을 하고자 한다.
VQ-VAE
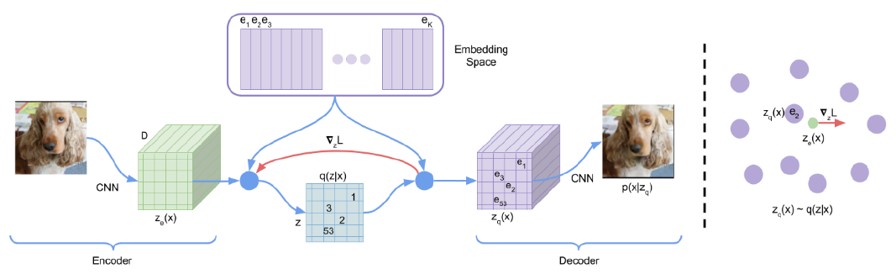
- VQ-VAE는 Vector Quantization과 VAE를 결합한 모델
- Vector quantization을 통해 VQ-VAE는 분산으로 생기는 문제들을 억제
- Posterior Collapse 없음
- Encoder, decoder, codebook 구조
- Codebook이란 위 그림에서 embedding space에 나타난 부분을 뜻하며, 본 그림에서는 embedding vector가 K개 있다는 것을 표현한다.
- Encoder에서 산출된 output은 embedding space에서 가장 가까운 embedding vector를 찾게 되며 해당 방식이 기존 VAE와 유사하다 여겨 저자들은 이 방식에 VQ-VAE라는 이름을 붙였다.
- 궁극적으로 VQ-VAE는 이미지 생성에 있어 고화질의 이미지는 reasonable한 속도와 좋은 품질을 유지한채 생성하지는 못한다는 단점이 있다.
PixelSnail
![]()
![]() Attention block을 이용하여 autoregressive model에 self attention을 구현
Attention block을 이용하여 autoregressive model에 self attention을 구현
- 과거의 정보에 접촉을 하는 병목구간이 해소
- 모든 conditionals을 모든 context를 참조할 수 있게 만듦
- 모든 spatial location에서 feature vector에 대해 하나의 key-value lookup을 적용
- Projects the input to a lower dimensionality to produce the keys and values and then uses softmax attention
3. VQ-VAE-2
다음과 같은 two-stage approach를 취한다 1) Discrete latent space에 이미지를 인코드하기 위해 hierarchical VQ-VAE를 훈련 2) 전체 데이터에서 유도된 강력한 PixelCNN prior를 이 discrete latent space에 fit
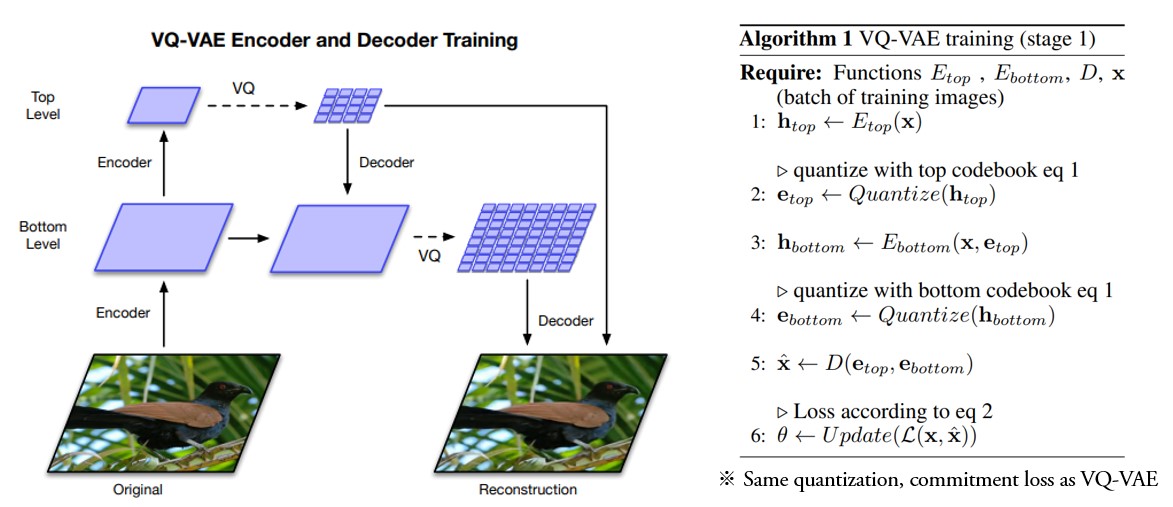
VQ-VAE-2는 VQ-VAE의 기조를 유지한 채 높은 해상도의 이미지들을 생성하기 위해 hierarchical한 구조를 이용한다. 각 계층 마다의 prior는 각 층에서 존재하는 상관 관계들을 포착하도록 만들어져있다. 본 논문에서는 2-layered hierarchy를 적용했을 때의 그림을 보여주는데, 이 경우 top latent는 global information을 갖고있고 bottom latent는 local detail을 담고 있다. VQ-VAE-2의 구조상 N-layered hierarchy가 가능하며 computation을 더 활용해 고해상도의 이미지를 생성할 수 있지만, 본 논문에서는 N=2,3만 보여주는데 이는 저자들이 reasonable 시간 동안 고해상도의 이미지를 생성 할 수 있느냐에 초점을 두고 있기 때문이다. Algorithm 1의 3에서 볼 수 있듯 bottom latent는 top latent에 의거하는데 이는 top latent code가 세부적인 특징까지 모두 모델링하려고 하는 현상을 방지하며, 각 계층이 개별적으로 픽셀에 대해 조건화 될 수 있어 decoder의 재구성 오류를 감소시킨다.
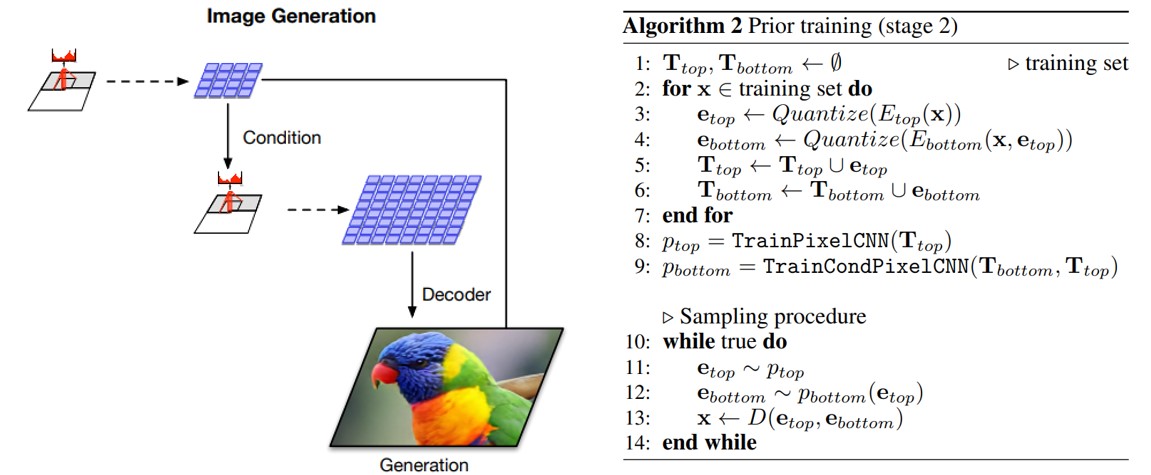
본 논문에서는 이미지를 더 압축하고 위의 과정에서 학습한 모델에서 샘플을 추출할 수 있도록 latent code에 대한 prior를 학습한다. 훈련 데이터에서 신경망을 사용하여 prior distribution을 fit하는 행위는 latent variable model의 성능을 크게 향상시킬 뿐만 아니라 marginal posterior와 prior 사이의 격차를 감소시키기 때문에 생성 모델에서는 관행이라고도 볼 수 있다. VQ-VAE-2에서 prior는 PixelCNN과 같은 강력한 autoregressive 신경망을 사용하여 만들어진다. Top latent map는 PixelSnail에서 본 것과 같이 multi-headed self-attention layer를 사용하는 데, 이는 top latent map의 경우 전역적인 정보를 담고 있어 이미지에서 멀리 떨어져 있는 pixel들의 상관 관계를 포착하기 위해 더 큰 수용영역(receptive field)을 사용하는 것이 유리하기 때문이다. 반면, bottom latent map의 경우는 지엽적인 정보를 담고 있으며, 더 많은 수의 pixel 에 대한 정확한 정보를 담고 있다. 이 경우 top level prior와 같이 self-attention layer를 사용하는 것은 메모리 제약에 걸려 비효율적이고, 어려워진다. 따라서 bottom level prior는 top level prior에서 비롯된 정보를 바탕으로 large conditioning stack을 사용하며 양호한 결과를 도출한다.
Maximum likelihood 모델들은 모든 학습 데이터 분포를 모델링하는 것이 강제되는데, 이는 해당 모델들의 목표가 데이터와 모델 분포 사이의 forward KL-divergence라고 할 수 있기 때문이다. 데이터 분포의 모든 mode를 적용하는 것은 굉장히 바람직하지만, 현재 데이터에 있는 모든 mode를 fit해야하기 때문에 GAN과 같은 adversarial 모델들에 비해서 굉장히 난이도가 높은 작업이다. 따라서, 본 논문에서 저자들은 샘플이 실제 데이터 manifold에 가까울수록 pre-trained classifier에 의해 올바른 class label로 분류될 가능성이 높다는 직관에 기반하여 생성되는 샘플의 다양성과 품질을 trade-off하는 방법을 제안한다.
4. Experiment
VQ-VAE-2의 성능을 2019년 state-of-the-art GAN인 BigGAN-deep과 비교한다.


VQ-VAE-2의 결과물은 BigGAN-deep에 비해서 같은 레이블의 다양한 결과물을 내는 것을 볼 수 있다.
저자들은 다음과 방식을 사용하여 VQ-VAE-2와 GAN based 샘플의 품질과 다양성을 측정한다.
Negative Log-Likelihood and Reconstruction Error Precision-Recall Metric Classification Accuracy Score FID and Inception Score(IS)
위의 방식들 중 precision-recall metric, classification accuracy score, FID and inception score는 다른 연구에서 자주 사용되는 반면 본 논문의 저자들은 이러한 sample-based metric은 샘플의 품질과 다양성에 대한 proxy를 제공할 뿐, 이미지에 대한 일반화는 무시하기 평가요소로써 부적절하다고 주장한다.
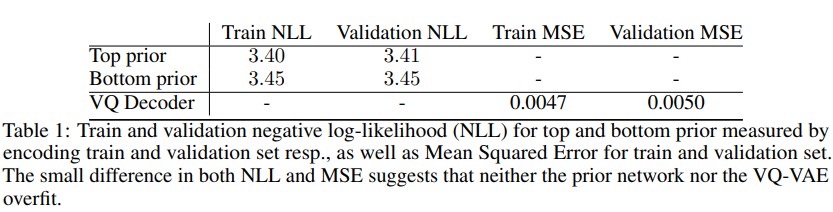
Table1을 토대로 train NLL과 validation NLL이 유사한 것은 prior network에 overfitting이 발생하지 않았다는 것을, train MSE와 validation MSE가 유사한 것은 VQ-VAE-2 자차에 overfitting이 없다는 것을 뜻한다.
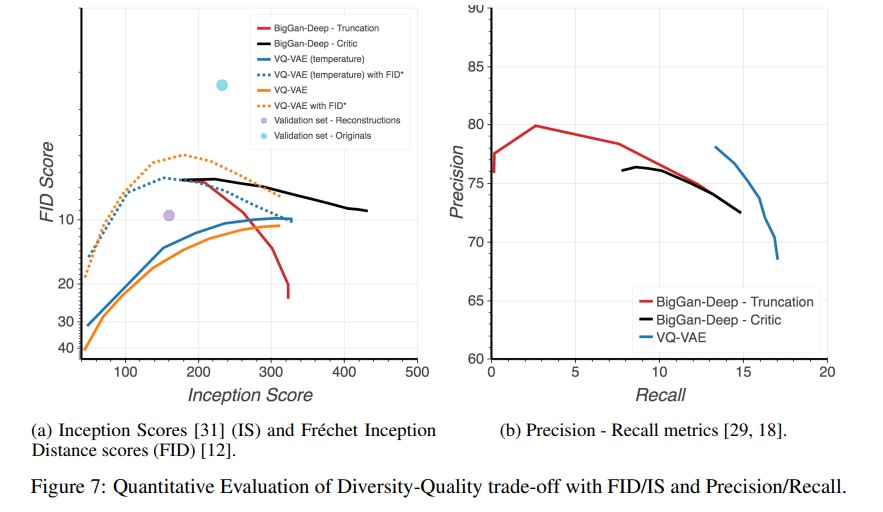
Figure7(a)는 FID와 IS를 볼 수 있다. 이 테스트의 경우 본 논문에서는 classifier-based rejection sampling을 사용하여 다양성과 품질을 trade-off해서 test상 성능을 높히는 방식이 사용됐는데, VQ-VAE-2와 BigGAN-deep 모두 해당 방식은 FID와 IS에서 모두 고평가를 받는다. 실험 결과 original을 사용할 경우 FID~2(청색 점), reconstruction의 경우 FID~10(보라색 점) 인 것을 통해 inception classifier는 VQ-VAE-2 reconstruction에서 나타는 선명도 저하 등에 민감하게 반응한다는 것을 알 수 있는데, inception network 통계가 실제 이미지와 유사하다는 것을 보이기 위해 VQ-VAE-2 샘플과 reconstruction 간의 FID를 연산한다.(FID*)
Figure7(b)는 VQ-VAE-2와 다양한 BigGan-deep에 대한 precision-recall을 보인다. VQ-VAE-2는 낮은 정확도를 보이지만 높은 recall을 보인다.
5. Conclusion
본 논문은 VQ-VAE를 계층 구조로 확장한 VQ-VAE-2를 보인다. VQ-VAE-2는 n개의 계층을 사용하여 기존의 방식보다 더욱 큰, 선명한 이미지를 처리할 수 있으며 이는 state-of-the-art GAN에 비해 생성 이미지의 다양성을 보장하면서도 정확도 또한 뒤쳐지지 않는다.
Subscribe via RSS